|
|

|
Новости
Статьи
Магазин
Драйвера
Контакты
RSS канал новостей
Программаторы 25 SPI FLASH
Адаптеры Optibay HDD Caddy
Драйвера nVidia GeForce
Драйвера AMD Radeon HD
Игры на DVD
Сравнение видеокарт
Сравнение процессоров
 В конце марта компания ASRock анонсировала фирменную линейку графических ускорителей Phantom Gaming. ...  Компания Huawei продолжает заниматься расширением фирменной линейки смартфонов Y Series. Очередное ...  Компания Antec в своем очередном пресс-релизе анонсировала поставки фирменной серии блоков питания ...  Компания Thermalright отчиталась о готовности нового высокопроизводительного процессорного кулера ...  Компания Biostar сообщает в официальном пресс-релизе о готовности флагманской материнской платы ... |
АРХИВ СТАТЕЙ ЖУРНАЛА «МОЙ КОМПЬЮТЕР» ЗА 2002 ГОДИскательные алгоритмы
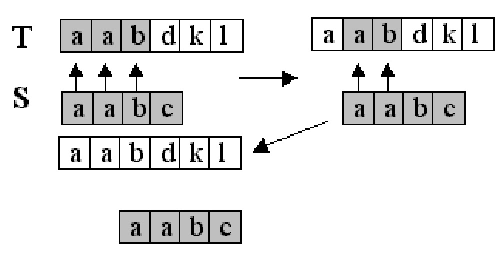
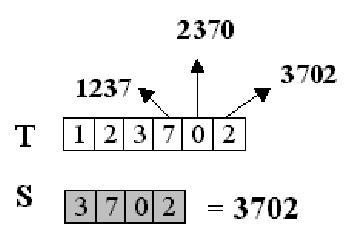
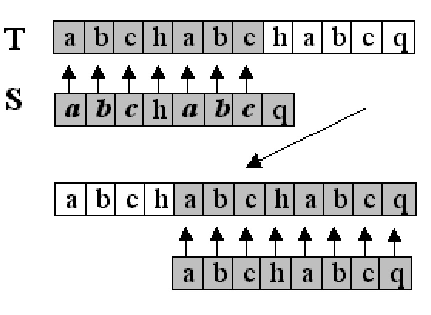
Владимир ТКАЧУК vova.tkachuk@fm.ua Те, кто имеет несчастье часто работать с текстовыми редакторами, знают цену функции нахождения нужных слов в тексте, существенно облегчающей редактирование документов и поиск нужной информации. Господа программисты тоже это знают, благо вплоть до самой компиляции программы им приходится работать в текстовом редакторе. Впрочем, мы с вами собрались не затем, чтобы расхваливать эту почтенную фичу, а чтобы разобраться, как это работает и как это можно реализовать на практике. Конечно, сейчас функции поиска инкапсулированы во многие языки программирования высокого уровня — чтобы установить цензуру на своем чате, вы, скорее всего, воспользуетесь уже готовым скриптом. Но если вдруг вы задумаете писать принципиально новый редактор, знать принципы организации функций поиска будет совсем нелишне. Кроме того, в готовых самплах тоже далеко не всегда все написано лучшим образом. Наконец, область применения функции поиска, как вы понимаете, не ограничивается одними лишь текстовыми редакторами… Итак, пусть у нас есть текст, состоящий из n символов, который в дальнейшем договоримся называть T, а T[i] — его i-ый символ. Строку или просто слово, состоящее из m символов, назовем S, где S[i] —i-ый символ строки. Нам нужно проверить, входит ли данная строка в данный текст, и если входит, то начиная с какого символа текста. В этой статье мы рассмотрим несколько известных алгоритмов, решающих поставленную задачу. Простейший алгоритм Суть метода, о котором пойдет речь ниже, заключается в следующем: мы проверяем, совпадают ли m символов текста (начиная с выбранного) с символами нашей строки, пытаясь примерить шаблон куда только возможно (Рис. 1). Естественно, реализовать описанный алгоритм проще всего (код на языке Pascal): Просто и элегантно, вроде так и надо. Действительно, это несложно в исполнении, но и не очень эффективно на практике. Давайте оценим скорость работы этой программки. В ней присутствуют два цикла (один вложенный), время Как вы уже, наверное, поняли, основной недостаток вышеизложенного метода состоит в том, что приходится выполнять много лишней работы. Например, найдя строку aabc и обнаружив несоответствие в четвертом символе (совпало только aab), алгоритм будет продолжать сравнивать строку, начиная со следующего символа, хотя это однозначно не приведет к результату. Следующий метод работает намного быстрее простейшего, но, к сожалению, накладывает некоторые ограничения на текст и искомую строку. Алгоритм Рабина-Карпа Идея, предложенная Рабином и Карпом, подразумевает поставить в соответствие каждой строке некоторое уникальное число, и вместо того чтобы сравнивать сами строки, сравнивать числа, что намного быстрее (Рис. 2). Проблема в том, что искомая строка может быть длинной, строк в тексте тоже хватает. А так как каждой строке нужно сопоставить уникальное число, то и чисел должно быть много, а стало быть, числа будут большими (порядка Dm, где D — количество различных символов), и работать с ними будет так же неудобно. Ниже вы узнаете, как найти выход из этого положения, а пока смотрите реализацию для текста, состоящего только из цифр, и строки длиной до 8 символов. Этот алгоритм выполняет линейный проход по строке (m шагов) и линейный проход по всему тексту (n шагов), стало быть, общее время работы есть O(n+m). Это время линейно зависит от размера строки и текста, стало быть программа работает быстро. Но какой интерес работать только с короткими строками и цифрами? Разработчики алгоритма придумали, как улучшить этот алгоритм без особых потерь в скорости работы. Как вы заметили, мы ставили в соответствие строке ее числовое представление, но возникала проблема больших чисел. Ее можно избежать, если производить все арифметические действия по модулю какого-то простого числа (постоянно брать остаток от деления на это число). Таким образом, находится не само число, характеризующие строку, а его остаток от деления на некое простое число. Теперь мы ставим число в соответствие не одной строке, а целому классу, но так как классов будет довольно много (столько, сколько различных остатков от деления на это простое число), то Итак, нам все-таки приходится производить сравнение строк посимвольно, но так как «холостых» срабатываний будет немного (в 1/P случаях), то ожидаемое время работы малое. Строго говоря, время работы есть O(m+n+mn/P), mn/P достаточно невелико, так что сложность работы почти линейная. Понятно, что простое число следует выбирать большим, чем больше это число, тем быстрее будет работать программа. Этот алгоритм значительно быстрее предыдущего и вполне подходит для работы с очень длинными строками. Еще один важный метод, о котором я хочу рассказать, — алгоритм Кнута-Морриса-Пратта, один из лучших на нынешний момент, работает за линейное время для любого текста и любой строки. Алгоритм Кнута-Морриса-Пратта Метод использует предобработку искомой строки, а именно: на ее основе создается так называемая префикс-функция. Суть этой функции в нахождении для каждой подстроки S[1..i] строки S наибольшей подстроки S[1..j] (j<i), присутствующей одновременно и в начале, и в конце подстроки (как префикс и как суффикс). Например, для подстроки abcHelloabc такой подстрокой является abc (одновременно и префиксом, и суффиксом). Смысл префикс-функции в том, что мы можем отбросить заведомо неверные варианты, т.е. если при поиске совпала подстрока abcHelloabc (следующий символ не совпал), то нам имеет смысл продолжать проверку продолжить поиск уже с четвертого символа (первые три и так совпадут) (Рис. 3). Вот как можно вычислить эту функцию для всех значений параметра от 1 до m: Теперь разберемся, почему же данная процедура вычисляет префикс-функцию Доказать что эта программа работает за линейное время, можно точно так же, как и для процедуры Prefix. Стало быть, общее время работы программы есть O(n+m), т. е. линейное время. Напоследок хочу заметить, что простейший алгоритм и алгоритм Кнута-Морриса-Пратта помимо нахождения самих строк считают, сколько символов совпало в процессе работы. И еще: алгоритм Кнута-Морриса-Пратта немногим более громоздок, чем простейший, зато работает намного быстрее. Так что делайте выводы. P.S. Все программы проверены на работоспособность, достаточно вставить соответствующие сегменты кода вместо многоточий. Рекомендуем ещё прочитать:
|
|
|
 Идёт загрузка...
Идёт загрузка...| Хостинг на серверах в Украине, США и Германии. | © sector.biz.ua 2006-2015 design by Vadim Popov |