|
|

|
Новости
Статьи
Магазин
Драйвера
Контакты
RSS канал новостей
Программаторы 25 SPI FLASH
Адаптеры Optibay HDD Caddy
Драйвера nVidia GeForce
Драйвера AMD Radeon HD
Игры на DVD
Сравнение видеокарт
Сравнение процессоров
 В конце марта компания ASRock анонсировала фирменную линейку графических ускорителей Phantom Gaming. ...  Компания Huawei продолжает заниматься расширением фирменной линейки смартфонов Y Series. Очередное ...  Компания Antec в своем очередном пресс-релизе анонсировала поставки фирменной серии блоков питания ...  Компания Thermalright отчиталась о готовности нового высокопроизводительного процессорного кулера ...  Компания Biostar сообщает в официальном пресс-релизе о готовности флагманской материнской платы ... |
АРХИВ СТАТЕЙ ЖУРНАЛА «МОЙ КОМПЬЮТЕР» ЗА 2002 ГОДПорядочные алгоритмы
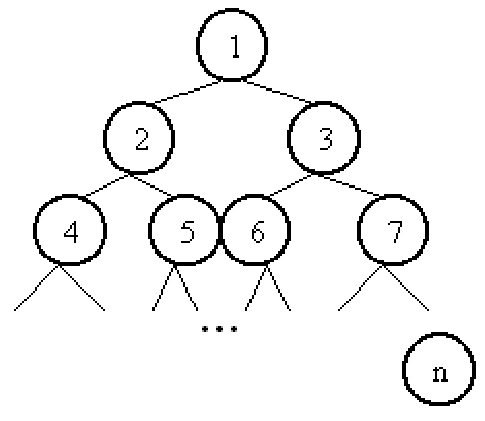
Владимир ТКАЧУК vova.tkachuk@ua.fm (Окончание, начало см. в МК № 28 (199)) Алгоритм 5. Сортировка двоичной кучей Проблема первых трех алгоритмов, описанных в прошлой части статьи, состояла в том, что после того как элемент занимал свое место, информация об уже произведенных сравнениях никак не использовалась. Структура двоичного дерева позволяет сохранить эту информацию. Итак, представим массив в виде дерева (Рис. 1). Корень дерева — элемент с индексом 1; элемент с индексом i является «родителем» для элементов с индексами 2*i и 2*i+1, а те, в свою очередь, являются его «детьми». Каждый элемент кроме первого имеет «родителя» и может иметь до двух «детей» — речь ведь идет именно о ДВОИЧНОМ дереве. Очевидно, что корнем дерева является наименьший элемент, а наибольший не имеет детей. Тут возникают два вопроса: как нам такую кучу наплодить? И зачем нам это вообще нужно? Пренебрегая порядком, отвечу сразу на второй вопрос: мы хотим извлечь из кучи минимальный элемент, а потом как-то преобразовать и восстановить кучу. Таким образом, по очереди извлечь все элементы и получить отсортированный массив. И вот как мы собираемся это сделать: пусть поддеревья с корнями 2*i и 2*i+1 уже имеют свойство кучи, мы же хотим, чтобы такое свойство имело и поддерево с корнем i. Для этого, если корень больше наименьшего своего «ребенка», мы меняем корень дерева (элемент с индексом i) с этим «ребенком», после повторяем алгоритм для поддерева, куда перешел бывший корень. Выполняя этот алгоритм «снизу вверх» (сначала для маленьких поддеревьев, потом для больших), мы добьемся того, что свойство кучи будет выполняться для всего дерева. Извлечение элемента происходит очень простым способом: мы ставим последний элемент на первое место и запускаем алгоритм исправления кучи от корня дерева… Я тут много наговорил, но на А теперь главное, т. е. оценка сложности. Время работы процедуры исправляющей кучу зависит от высоты дерева. Высота всего дерева равна log2n, значит, время работы процедуры есть O(log2n). Программа состоит из двух частей: формирование кучи и создание отсортированного массива B. Время исполнения каждой из частей не больше O(n log2n) (в каждой части исправляющая процедура вызывается не более n раз). Значит, время работы то же, что и в сортировке слиянием. Теперь лирическое отступление насчет времени работы. Может, читатель думает, что быстрые алгоритмы сложны в исполнении и проще написать что-то вроде сортировки вставками. Что ж, рассмотрим простой пример: допустим, вы написали сортировку вставками, тщательно, с помощью ассемблера, и время работы получилось 2n2, а какой-нибудь раздолбай написал сортировку слиянием со временем работы 50nlog2n. И тут появилась необходимость отсортировать 1000000 элементов (что в наше время не редкость). Вы использовали крутой компьютер, который делает 108 операций сравнения и перестановки в секунду, а у него компьютер похуже — всего 106 операций в секунду. И вы будете ждать 2*(106)2/108 = 20 000 секунд (приблизительно 5.56 часов), а ваш конкурент —50*(106)*log2(106)/106 = 1000 секунд (приблизительно 17 минут). Надеюсь, вы проведете это время (5 часов) с пользой для себя и поймете, что хороший алгоритм — быстрый алгоритм :-). Хотя, если вы будете сортировать маленький массив или много маленьких массивов, то 2n2 для вас будет лучше, чем 50nlog2n. Эту закономерность использует один из способов оптимизации сортировки слиянием: сортировать маленькие части массива вставками. Теперь переходим к самому интересному, а именно к одной из самых быстрых и эффективных из известных сортировок, которая так и называется — «быстрая сортировка». Алгоритм 6. Быстрая сортировка. Как и в сортировке слиянием, массив разбивается на две части, с условием, что все элементы первой части меньше любого элемента второй. Потом каждая часть сортируется отдельно. Разбиение на части достигается упорядочиванием относительно некоторого элемента массива, т. е. в первой части все числа меньше либо равны этому элементу, а во второй, соответственно, больше либо равны. Два индекса проходят по массиву с разных сторон и ищут элементы, которые попали не в свою группу. Найдя такие элементы, их меняют местами. Тот элемент, на котором индексы пересекутся, и определяет разбиение на группы. Классическая реализация алгоритма выглядит так: Что же делает данный алгоритм таким быстрым? Ну во-первых, если массив каждый раз будет делится на приблизительно равные части, то для него будет верно то же соотношение, что и для сортировки слиянием, т. е. время работы будет O(nlog2n). Это уже само по себе хорошо. Кроме того, константа при nlog2n очень мала, ввиду простоты внутреннего цикла программы. В комплексе это обеспечивает огромную скорость работы. Но как всегда есть одно «но». Вы, наверное, уже задумались: а что если массив не будет делится на равные части? Классическим примером является попытка «быстро» отсортировать уже отсортированный массив. При этом данные каждый раз будут делиться в пропорции 1 к n-1, и так n раз. Общее время работы при этом будет O(n2), тогда как вставкам, для того чтобы «понять», что массив уже отсортирован, требуется всего-навсего O(n). А на кой нам сортировка, которая одно сортирует хорошо, а другое плохо? А собственно, что она сортирует хорошо? Оказывается, что лучше всего она сортирует случайные массивы (порядок элементов в массиве случаен). И поэтому нам предлагают ввести в алгоритм долю случайности. А точнее, вставить randomize и вместо r:=A[p]; написать r:=A[random(q-p)+p]; т. е. теперь мы разбиваем данные не относительно конкретного, а относительно случайного элемента. Благодаря этому алгоритм получает приставку к имени «вероятностный». Особо недоверчивым предлагаю на своем опыте убедится, что данная модификация быстрой сортировки сортирует любые массивы столь же быстро. А теперь еще один интересный факт: время O(nlog2n) является минимальным для сортировок, которые используют только попарное сравнение элементов и не использует структуру самих элементов. Тем, кому интересно, откуда это взялось, рекомендую поискать в литературе, доказательство я здесь приводить не намерен, не Дональд Кнут, в конце концов :-). Но вы обратили внимание, что для рассмотренных алгоритмов в принципе не важно, что сортировать — такими методами можно сортировать хоть числа, хоть строки, хоть какие-то абстрактные объекты. Следующие сортировки могут сортировать только определенные типы данных, но за счет этого они имеют рекордную временную оценку O(n). Алгоритм 7. Сортировка подсчетом. Этот метод подходит для сортировки целых чисел из не очень большого диапазона (сравнимого с размером массива). Идея вот в чем: для каждого элемента найти, сколько элементов, меньших определенного числа, и поместить это число на соответствующие место. Делается это так: за линейный проход по массиву мы для каждого из возможных значений подсчитываем, сколько элементов имеют такое значение. Потом добавляем к каждому из найденных чисел суму всех предыдущих. Получая, таким образом, сколько есть элементов, значения которых не больше данного значения. Далее, опять-таки за линейный проход, формируем из исходного массива новый отсортированный. При этом следим, чтобы два одинаковых элемента не были записаны в одно место. Если все равно непонятно, смотрите реализацию: Этот простой метод не использует вложенных циклов и, учитывая небольшой диапазон значений, время его работы есть O(n). Рассмотрев такое количество сортировок, можно задуматься: а будет ли результат их работы одинаковым? Странный вопрос, ведь все сортировки правильно сортируют данные, так почему же результат работы может быть разным? Хорошо, объясню: меньшие элементы всегда расположены перед большими, но порядок одинаковых элементов может быть нарушен. Если мы сортируем данные, которые состоят из одного ключа, то мы, конечно, не заметим разницы. Но если к ключу прилагается дополнительная информация, то одна сортировка может вернуть нам 1977 "Иванов" и 1977 "Сидоров", а другая —1977 "Сидоров" и 1977 "Иванов". Значит, порядок одинаковых элементов может в процессе сортировки стать другим. Правда, это бывает далеко не всегда и не в каждой сортировке. В сортировках вставками, пузырьком, подсчетом и слиянием порядок элементов с одинаковыми ключами всегда такой же, как и в изначальном массиве. Такие сортировки называются устойчивыми, и сейчас я познакомлю вас с улучшенной сортировкой подсчетом, которая позволяет сортировать числа большего диапазона, используя другую устойчивую сортировку. Алгоритм 8. Цифровая сортировка. Этой сортировкой можно сортировать целые неотрицательные числа большого диапазона. Идея состоит в следующем: отсортировать числа по младшему разряду, потом устойчивой сортировкой сортируем по второму, третьему, и так до старшего разряда. В качестве устойчивой сортировки можно выбрать сортировку подсчетом, в виду малого времени работы. Реализация такова: Так как сортировка подсчетом вызывается константное число раз, то время работы всей сортировки есть O(n). Заметим, что таким способом можно сортировать не только числа, но и строки, если же использовать сортировку слиянием в качестве устойчивой, то можно сортировать объекты по нескольким полям. Теперь вы владеете достаточным арсеналом, чтобы сортировать все что угодно и как угодно. Помните, что выбор нужной вам сортировки зависит от того, какие данные вы будете сортировать и где вы их будете сортировать. P.S. Все программы рабочие — если, конечно, вам не лень будет заменить три точки на код ввода и вывода массивов :-). Рекомендуем ещё прочитать:
|
|
|
 Идёт загрузка...
Идёт загрузка...| Хостинг на серверах в Украине, США и Германии. | © sector.biz.ua 2006-2015 design by Vadim Popov |