|
|

|
Новости
Статьи
Магазин
Драйвера
Контакты
RSS канал новостей
Программаторы 25 SPI FLASH
Адаптеры Optibay HDD Caddy
Драйвера nVidia GeForce
Драйвера AMD Radeon HD
Игры на DVD
Сравнение видеокарт
Сравнение процессоров
 В конце марта компания ASRock анонсировала фирменную линейку графических ускорителей Phantom Gaming. ...  Компания Huawei продолжает заниматься расширением фирменной линейки смартфонов Y Series. Очередное ...  Компания Antec в своем очередном пресс-релизе анонсировала поставки фирменной серии блоков питания ...  Компания Thermalright отчиталась о готовности нового высокопроизводительного процессорного кулера ...  Компания Biostar сообщает в официальном пресс-релизе о готовности флагманской материнской платы ... |
АРХИВ СТАТЕЙ ЖУРНАЛА «МОЙ КОМПЬЮТЕР» ЗА 2002 ГОДПорядочные алгоритмы
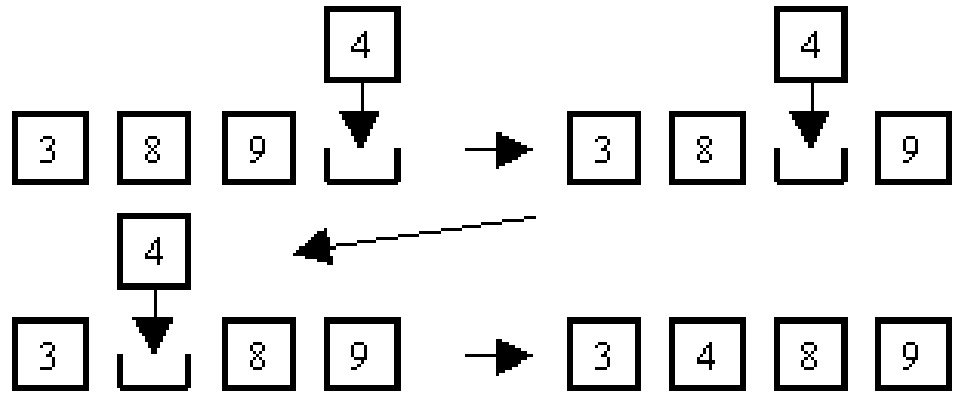
Владимир ТКАЧУК vova.tkachuk@ua.fm Еще в раннем детстве в нас просыпается стремление к разрушению и хаосу — один их базовых инстинктов человека. Но по мере взросления в нем крепнет противоположное начало — тяга к упорядочиванию и систематизации. Появление компьютеров дало возможность работать с куда большими объемами информации. Проблема упорядочивания стала более остро, на нее были кинуты силы лучших умов. В прикладной математике она получила название «задача сортировки». Надо отдать должное исследователям, постарались они хорошо. Об этом свидетельствует то огромное количество методов, которыми нам предлагают сортировать данные. Зачем же так много? И правда — может, достаточно одного эффективного способа, и не надо морочить себе голову таким обилием? Ответ на этот вопрос состоит в том, что очень трудно иногда бывает сопоставить эффективность двух разных методов. Проще говоря: одни более удобны в одних случаях, другие — в других. Проблемам сортировок Дональд Кнут посвятил целый том своего «Искусства программирования». Попробуем и мы разобраться в этом подробней. Итак, постановка задачи такова: есть набор неупорядоченных данных (массив), задача — выдать те же данные, упорядоченные по некоторому полю (ключу) по возрастанию (убыванию). Обычно данные представляются в виде ключа и некоторой связанной с ним информации. Например, год рождения и фамилия. Рассмотрим несколько алгоритмов, решающих данную задачу. Алгоритм 1. Сортировка вставками. Это изящный и простой для понимания метод. Вот в чем его суть: создается новый массив, в который мы последовательно вставляем элементы из исходного массива так, чтобы новый массив был упорядоченным. Вставка происходит следующим образом: в конце нового массива выделяется свободная ячейка, далее анализируется элемент, стоящий перед пустой ячейкой (если, конечно, пустая ячейка не стоит на первом месте), и если этот элемент больше вставляемого, то подвигаем элемент в свободную ячейку (при этом на том месте, где он стоял, образуется пустая ячейка) и сравниваем следующий элемент. Так мы прейдем к ситуации, когда элемент перед пустой ячейкой меньше вставляемого, или пустая ячейка стоит в начале массива. Помещаем вставляемый элемент в пустую ячейку (Рис. 1). Таким образом, по очереди вставляем все элементы исходного массива. Очевидно, что если до вставки элемента массив был упорядочен, то после вставки перед вставленным элементом расположены все элементы, меньшие его, а после — большие. Так как порядок элементов в новом массиве не меняется, то сформированный массив будет упорядоченным после каждой вставки. А значит, после последней вставки мы получим упорядоченный исходный массив. Вот как такой алгоритм В принципе, данную сортировку можно реализовать и без дополнительного массива B, если сортировать массив A сразу при считывании, т. е. осуществлять вставку нового элемента в массив A. Алгоритм 2. Пузырьковая сортировка. Реализация данного метода не требует дополнительной памяти. Метод очень прост и состоит в следующем: берется пара рядом стоящих элементов, и если элемент с меньшим индексом оказывается больше элемента с большим индексом, то мы меняем их местами. Эти действия продолжаем, пока есть такие пары. Легко понять, что когда таких пар не останется, то данные будут отсортированными. Для упрощения поиска таких пар данные просматриваются по порядку от начала до конца. Из этого следует, что за такой просмотр находится максимум, который помещается в конец массива, а потому следующий раз достаточно просматривать уже меньшее количество элементов. Максимальный элемент как бы всплывает вверх, отсюда и название алгоритма (Рис. 2). Так как каждый раз на свое место становится по крайней мере один элемент, то не потребуется более N проходов, где Алгоритм 3. Сортировка Шейкером. Когда данные сортируются не в оперативной памяти, а на жестком диске, особенно если ключ связан с большим объемом дополнительной информации, то количество перемещений элементов существенно влияет на время работы. Этот алгоритм уменьшает количество таких перемещений, действуя следующим образом: за один проход из всех элементов выбирается минимальный и максимальный. Потом минимальный элемент помещается в начало массива, а максимальный, соответственно, в конец. Далее алгоритм выполняется для остальных данных. Таким образом, за каждый проход два элемента помещаются на свои места, а значит, понадобится N/2 проходов, где N — количество элементов. Реализация данного алгоритма выглядит так: Рассмотрев эти методы, сделаем определенные выводы. Их объединяет не только то, что они сортируют данные, но также и время их работы. В каждом из алгоритмов присутствуют вложенные циклы, время выполнения которых зависит от размера входных данных. Значит, общее время выполнения программ есть O(n2) (константа, умноженная на n2). Следует отметить, что первые два алгоритма используют также O(n2) перестановок, в то время как третий использует их O(n). Отсюда следует, что метод Шейкера является более выгодным для сортировки данных на внешних носителях информации. Если вы думаете, что бравые «алгоритмщики» остановились на достигнутом, то вы ошибаетесь. Видите ли, временная оценка O(n2) показалась им слишком громоздкой, и они, жадины такие, решили еще потратить свое время, чтобы впоследствии сэкономить наше. Итак, давайте теперь рассмотрим более быстрые алгоритмы. Алгоритм 4. Сортировка слиянием. Эта сортировка использует следующую подзадачу: есть два отсортированных массива, нужно сделать (слить) из них один отсортированный. Алгоритм сортировки работает по такому принципу: разбить массив на две части, отсортировать каждую из них, а потом слить обе части в одну отсортированную. Корректность данного метода практически очевидна, поэтому перейдем к реализации. Чтобы оценить время работы этого алгоритма, составим рекуррентное соотношение. Пускай T(n) — время сортировки массива длины n, тогда для сортировки слиянием справедливо T(n)=2T(n/2)+O(n) (O(n) — это время, необходимое на то, чтобы слить два массива). Распишем это соотношение: Осталось оценить k. Мы знаем, что 2k=n, а значит k=log2n. Уравнение примет вид T(n)=nT(1)+ log2nO(n). Так как T(1) — константа, то T(n)=O(n)+log2nO(n)=O(nlog2n). То есть, оценка времени работы сортировки слиянием меньше, чем у первых трех алгоритмов (я прошу прощения у тех, кто не понял мои рассуждения или не согласен с ними, — просто поверьте мне на слово). Перед тем как объяснить, чем этот метод лучше, рассмотрим еще один алгоритм. (Продолжение следует) Рекомендуем ещё прочитать:
|
|
|

 Идёт загрузка...
Идёт загрузка...| Хостинг на серверах в Украине, США и Германии. | © sector.biz.ua 2006-2015 design by Vadim Popov |